第二十八期
2026-03-28
一. 用電腦養「龍蝦」? Openclaw是什麼
作者:Lhs
在前陣子,中國爆發了一陣「養龍蝦」風潮,每個人都在自己的頭像旁新增了一個龍蝦標誌,甚至有人專門砸下重金,只為了請專人在自己的電腦上「養龍蝦」
那麼問題來了,這個「龍蝦」究竟是何方神聖?
 (中國的養龍蝦熱潮 翻攝自網路)
(中國的養龍蝦熱潮 翻攝自網路)
走出對話框的AI:Openclaw
所謂的龍蝦實際上是由奧地利工程師彼得·斯坦伯格(Peter Steinberger)製作的AI:「Openclaw」,早在去年11月便已經推出。由於這款A的頭像是一隻小龍蝦,而這款AI需要培養才得以發揮其功效,因此被稱為「龍蝦」,而培養模型的過程則被稱為「養龍蝦」 Openclaw的特色在於,他能夠直接接管電腦中包括但不限於郵件寄送、社群文章撰寫與留言回復......等等多樣化的功能,根據培養的模型而定,他不在只是個困在對話框中的「工具」,而是個能夠幫你操控電腦工作的「助理」
 (Openclaw開發者 彼得·斯坦伯格 翻攝自網路)
(Openclaw開發者 彼得·斯坦伯格 翻攝自網路)
從「被動」走向「主動」
使用龍蝦究竟能帶來哪些幫助?為何那麼多人搶著安裝?實際上,只要模型訓練得夠好,這位AI助手能做到的事情包括但不限於以下幾項:
1.日常辦公自動化: 能夠幫忙收發電子郵件、清空收件匣、整理文件與資料、排程會議,甚至能將會議錄音整理成摘要並自動寄送給老闆 2.個人生活助理: 能夠協助訂機票、預訂飯店、辦理航班報到、規劃旅行行程,以及管理待辦事項與提醒 3.資料處理與主動回報: 能搜尋網路資訊、分析文件內容並建立知識庫。透過設定「心跳機制」,它還能主動定期檢查電郵或閱讀新聞,再向使用者回報重要資訊 4.社群與內容經營: 可以撰寫文章、自動發布社群貼文,以及回覆留言 5.自主學習與記憶累積: 具備名為「Soul.md」的架構(靈魂學習),可以累積對話內容、建立長期記憶,甚至透過與其他 AI 代理討論來學習新知識。
透過以上功能不難發現,Openclaw能辦的事情包山包海,如果權限在給多一些,運用層面再更廣一點,這位助手甚至能包辦使用者的生活。
但也因為功能與權限過廣,風險也隨之而生。
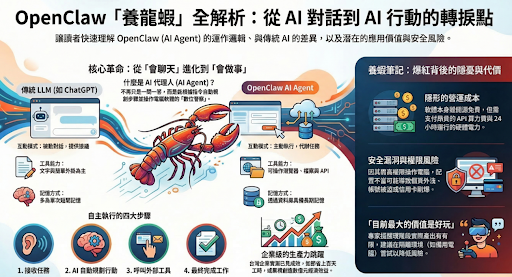 (龍蝦的功能與隱患 由noteookLM協助整理生成)
(龍蝦的功能與隱患 由noteookLM協助整理生成)
便利背後帶來的隱患
據專家研究,Openclaw的實際技能目前仍需改良,並且據研究發現,龍蝦不僅會受到提示詞攻擊,更甚至因為信任權限模糊而導致越權等行為,最嚴重更可能導致重要機密資訊被刪除,甚至外洩,中國官方也在前陣子發布安全警訊,各位讀者如果想要嘗試的話,還請多加注意
資料來源: iThome 全球爆紅的 OpenClaw,究竟是神藥還是鬧劇? 科技新報 BBC中文 紐約時報中文網
二. AI 的未來在哪裡?輝達 GTC 重點摘要
作者:YD
本週科技圈最熱的話題,莫過於 2026 NVIDIA GTC 大會了!執行長黃仁勳在長達兩個半小時的主題演講中,不僅再次讓全球見識到「AI 教父」的魅力,更宣告 AI 正式告別訓練階段與參數疊加,邁入真實環境應用的「推論時代(Inference Era)」。

兆元商機不是夢:AI 進入推論時代
黃仁勳在會上霸氣預測,到 2027 年,AI 基礎設施相關的需求將達到 1 兆美元,這整整比去年預估的數字翻了一倍。這股底氣來自於 AI 重心的轉移:現在的 AI 不再只是坐著「讀書(訓練)」,而是 24 小時在真實世界執行決策的「生產力核心」。黃仁勳更巧妙地把 AI 產業比喻成「五層蛋糕」,從最底層的能源、晶片、基礎設施,到上層的模型與應用,每一層都蘊藏巨大的商業潛力。
最強戰力登場:Vera Rubin 與「養龍蝦」熱潮
全新架構
這次大會的硬體主秀非 Vera Rubin 架構 莫屬。這套系統採用台積電先進製程與 HBM4 記憶體,運算效能較前代大幅躍進,每瓦效能提升達 35 倍 。
其中最重要的莫 Groq 所屬。去年底聖誕節前後輝達丟下震撼彈,宣布以 200 億收購 AI 推理晶片公司 Groq,創下輝達史上最高的收購交易。但值得注意的是也許是為了規避反壟斷調查或其他原因,這筆交易是以技術收購和公司人員轉移的方式進行,也意味著 Groq 這間公司仍然存在於世界上。
Groq 公司的 LPU (語言處理單元 Language Processing Unit)是專為語言模型打造的推論晶片,其特殊的設計使其能夠使用較低的成本、極低的延遲、較少的功耗完成相同的任務,這是過去輝達生態系所缺乏的。這次大會馬上就推出基於 LPU 3 所打造的機櫃 Groq 3 LPX,展現了公司高度的整合效率。

軟體生態
但最有趣的莫過於軟體生態,近期爆紅的個人 AI 助手 OpenClaw 因為標誌是一隻龍蝦,網友戲稱為「養龍蝦」;輝達順勢推出了企業版的 NemoClaw,讓公司行號也能安全、快速地部署具備自主行動能力的「AI 代理人(Agentic AI)」。
實體 AI 動起來:雪寶機器人與自駕車
機器人
AI 不只活在電腦裡,這次連迪士尼的 雪寶(Olaf)機器人 都現身與老黃互動,驚豔全場!這代表物理 AI(Physical AI)技術已趨成熟,未來將廣泛應用於工廠、家庭甚至太空資料中心。
自動駕駛
在交通方面,黃仁勳也宣佈與比亞迪、日產、吉利等大廠合作,並預計與 Uber 在多個城市部署 L4 等級的自動駕駛車隊,直言「自動駕駛的 ChatGPT 時刻已經到來」。
回顧一年多前的台北國際電腦展黃仁勳向大家介紹 Omniverse,再到今天雪寶機器人走上台和大家互動,我們一同見證了科技高速發展。歡迎回顧科技週刊第四期,比對看看一年多時間的發展。從效能逆天的晶片、全民瘋傳的「養龍蝦」代理平台,到走路超萌的雪寶,2026 GTC 告訴我們:AI 的未來不再是遙不可及的科幻片,它已經全面滲透到我們的工廠、街道,甚至是太空之中。
資料來源: NVIDIA GTC Keynote 2026 https://news.codecat.tw/4
三. AI 思維的革命:從「逐字打字」到「全局精煉」——Diffusion Language Model 的崛起
文/Ke.H
想像一下:傳統大型語言模型(LLM)像一台精密的打字機,一個字接一個字地輸出,每一步都嚴格依賴前一個字的決定。若中途選錯,便無法回頭,只能硬著頭皮繼續前進。這是我們熟悉的 AI「思維方式」——線性、因果、不可逆。 如今,一種全新的 AI 思維模式正在悄然興起。它不逐字敲擊鍵盤,而是從一團模糊的「噪聲」開始,像一位經驗豐富的畫家或編輯,反覆審視整份草稿,同時調整數百個細節,最終精煉出一篇連貫、精準的作品。這就是 Diffusion Language Model(擴散語言模型,簡稱 DLM)。 這種「全局迭代思維」不僅打破了自回歸(Autoregressive, AR)模型長達十年的主導地位,更在 2026 年初以 Mercury 2 的商業落地為標誌,宣告 AI 生成範式進入全新時代。它讓我們重新思考:AI 的「思考」究竟可以有多樣?本文將深入淺出地比較兩者原理、剖析技術變革,並探討這場思維革命對產業與未來的深遠影響。
傳統 AR 模型的「打字機思維」:線性因果的極致
自 2017 年 Transformer 架構問世以來,主流 LLM(如 GPT 系列、LLaMA、Claude)幾乎都採用自回歸生成方式。其核心原理極為直觀:
模型學習的目標是 p (x) = ∏ p (xi | x<i) ——即根據已生成的前文,逐一預測下一個 token。訓練時使用 next-token prediction,推論時則嚴格左到右展開。
這種思維方式的優點顯而易見: 訓練穩定、scaling law 清晰、生態成熟。 它讓 AI 學會了「預測未來」的線性邏輯,成就了今日的 ChatGPT 奇蹟。 然而,限制同樣深刻:
延遲累積:
生成長文或多步推理時,Time to First Token(TTFT)與整體 throughput 受限。即使有 speculative decoding 等優化,典型速度仍僅 50–200 tokens/s。
錯誤不可逆:
早期 token 一旦選錯,整段輸出便偏離軌道。模型無法「回頭修正」,猶如打字機卡紙。
單向上下文:
僅能關注前文,難以全局規劃,導致 reversal curse(反向推理困難)等頑疾。 這正是傳統 AI 的「思維局限」——它像流水線工人,只能一步步向前,無法同時審視全貌。
Diffusion 的起源:從圖像噪聲到語言精煉
擴散模型的根源可追溯至 2015 年 Sohl-Dickstein 等人的熱力學模擬研究。2020 年 Ho 等提出 Denoising Diffusion Probabilistic Models(DDPM)後,在圖像領域爆發:Stable Diffusion、DALL·E 2、Midjourney 讓人人成為藝術家。 其本質是模擬「加噪與去噪」的物理過程:
前向過程:
逐步加入高斯噪聲(或離散遮罩),讓乾淨數據逐漸變成純噪聲。
反向過程:模型學習從噪聲中逐步恢復原始數據。
這套機制在連續數據(如像素)上大放異彩。2022 年起,研究者開始將其遷移至離散的語言領域,誕生了 Diffusion Language Model。
與 AR 不同,DLM 的核心創新在於並行精煉(parallel refinement)。它不預測「下一個字」,而是從全遮罩(或純噪聲)序列開始,透過少量迭代步驟(通常 4–8 步),同時預測並修正多個 token。數學上,這對應離散 masked diffusion:
前向:
以機率 t 隨機遮罩 token,直至 t=1 時全遮罩。
反向:
模型 pθ(x{t-1} | x_t) 同時預測所有被遮罩位置,逐步 unmask 並優化。 這種「粗到細」的全局迭代,讓模型擁有雙向上下文與自我修正能力——正是人類寫作或思考時的真實過程:先有大綱,再反覆潤飾。
技術變革的核心對比:兩種 AI 思維的碰撞
為便於理解,以下表格直觀比較兩者:
 DLM 保留 Transformer backbone,卻徹底改變訓練與推論目標。這不是小修小補,而是架構級革新:AR 優化「預測」,DLM 優化「重建」。結果是,它在資料受限情境下效率更高,並天然解決 reversal curse 等 AR 頑疾。
DLM 保留 Transformer backbone,卻徹底改變訓練與推論目標。這不是小修小補,而是架構級革新:AR 優化「預測」,DLM 優化「重建」。結果是,它在資料受限情境下效率更高,並天然解決 reversal curse 等 AR 頑疾。
商業實證:Mercury 2 的「思考式擴散」革命
 (圖片來源:https://www.inceptionlabs.ai/blog/introducing-mercury-2)
(圖片來源:https://www.inceptionlabs.ai/blog/introducing-mercury-2)
2026 年 2 月,Inception Labs 推出的 Mercury 2 將 DLM 推向生產級高峰。它是全球首款具備可調「推理等級」(Instant / Low / Medium / High)的 reasoning diffusion LLM。
其創新在於:
並行精煉引擎:
從噪聲開始,少量步驟內同時生成與修正多 token,GPU 利用率大幅提升。
內建思考機制:
高推理模式下,先在 latent space 完成 Chain-of-Thought,再輸出。TTFT 雖略長(約 4–5 秒),但整體端到端延遲仍遠低於傳統 reasoning 模式。
實測表現:
throughput 達 1000+ tokens/s(Blackwell GPU),品質與 Claude 4.5 Haiku、GPT-5.2 Mini 相當;在 AIME 2025 等基準上取得 91.1 分。定價僅輸入 $0.25/M、輸出 $0.75/M tokens。
Mercury 2 的成功證明: 擴散思維不僅更快,還能讓「高智能」與「即時性」並存。它已支援 128 K 上下文、原生 tool use 與 RAG,在語音客服、程式碼迭代、多跳代理等 agentic 場景中展現壓倒性優勢。
更深層的思維啟示與未來展望
這場革命的意義遠超速度提升。它讓我們看見 AI 可以擁有「不同思維方式」:
AR 像嚴謹的邏輯學家,步步為營。
DLM 像直覺的藝術家,全局洞察後反覆打磨。
兩者互補,或許未來會出現混合架構(Block Diffusion 等),讓 AI 同時具備線性精準與全局靈活。隨著 LLaDA 系列從零預訓練到百億參數,以及多模態擴散的進展,DLM 正加速進入視覺-語言-動作統一生成領域。 對產業而言,這意味著即時語音代理、低延遲 coding 工具、高併發 RAG 系統的成本與體驗將大幅躍升。對研究者而言,它開啟了探索「AI 認知多樣性」的新大門:或許下一個突破,不再是更大模型,而是更像人類的多維思維。 當你下次與 AI 對話時,不妨問問自己:它此刻是在「打字」,還是「畫畫」?Diffusion Language Model 的崛起提醒我們——AI 的思維革命,才剛剛開始。 (本文參考《A Survey on Diffusion Language Models》(arXiv: 2508.10875)及 Inception Labs 官方發布資料,撰寫於 2026 年 3 月。歡迎讀者前往 Mercury 2 playground 親身體驗這場思維躍進。)
資料來源 : A Survey on Diffusion Language Models (arXiv: 2508.10875) Inception Labs 官方部落格 - Introducing Mercury 2 Inception Labs 官方網站 - Mercury 2 Playground Inception Labs 官方平台/API 入口